
Can AI models learn to classify strength and conditioning exercises after being given only one example of each exercise? This is the question that Michael Deyzel, an alumnus of the Department of Electrical and Electronic Engineering at Stellenbosch University (SU), and Dr Rensu Theart, senior lecturer at the same department, aim to answer in their latest research paper, which they presented at the IEEE/Computer Vision Foundation CVPR Workshop in Vancouver, Canada, earlier this year.
They say there is a need in the sports and fitness industry for a practical system that can identify and understand human physical activity to enable intelligent workout feedback and virtual coaching. This is where SU-EMD, a new kind of dataset filled with motion sequences of seven common strength and conditioning exercises, comes in. These sequences are captured by both markerless and marker-based motion capture systems. This data helps solve what’s known as the “one-shot skeleton action recognition problem” and contributes toward developing a system that could watch someone exercise, understand their movements, and then provide smart workout feedback or even virtual coaching.
Michael, who completed his master’s degree cum laude last year under the supervision of Dr Theart, says the collection and processing of the tons of data necessary to train AI models is expensive and time-consuming.
“As part of my research, we’ve shown that you can teach a model what an exercise looks like by giving only one example of an exercise action. We used a special type of neural network that can operate directly on human skeleton data, thereby learning its representation of what human movement looks like.
“We hope our findings contribute to developing an AI-enabled virtual personal fitness assistant,” he adds.
Their approach
The pair use a state-of-the-art graph convolutional network (GCN) system to differentiate between these actions. The GCN is like a sorting system that pushes dissimilar actions apart and pulls similar actions closer together. After some training, the GCN could correctly identify new actions 87.4% of the time with just one try.
The research also considered the impact of various factors through an ablation study. The bottom line is that this one-shot metric learning method could be a game-changer for classifying sports actions in a virtual coaching system, especially when users can only provide a few expert examples for enrolling new actions.
The impact
They have made significant strides toward creating a practical system recognising strength and conditioning movements in sports. They’ve introduced a unique dataset of skeleton-based exercises for strength and conditioning. These 840 samples across seven exercise action classes are now open for researchers studying action recognition in sports, health, and fitness.
They used their dataset as a one-shot test set to test the waters, training it on a separate large-scale dataset. They aimed to explore the potential of transferring spatial-temporal features using the top-tier ST-GCN architecture. They discovered that skeleton augmentations – such as random moving, rotation, frame dropping, and pivoting – combined with the multi-similarity loss gave them the best results on their validation set.
While their findings revealed that a standard ST-GCN trained as a feature embedding in a metric learning paradigm could compete but not surpass the current best practices, they made an exciting discovery. For the first time, they demonstrated that spatial-temporal features could be easily learned and transferred to classify entirely new classes of exercises with impressive accuracy.
This method could be employed to classify sports actions in virtual coaching systems, which is particularly useful when users can’t provide many expert examples for the enrolment of new moves.
*The original article was published on the website of the Department of Electrical and Electronic Engineering.
**You can read the complete research paper here.
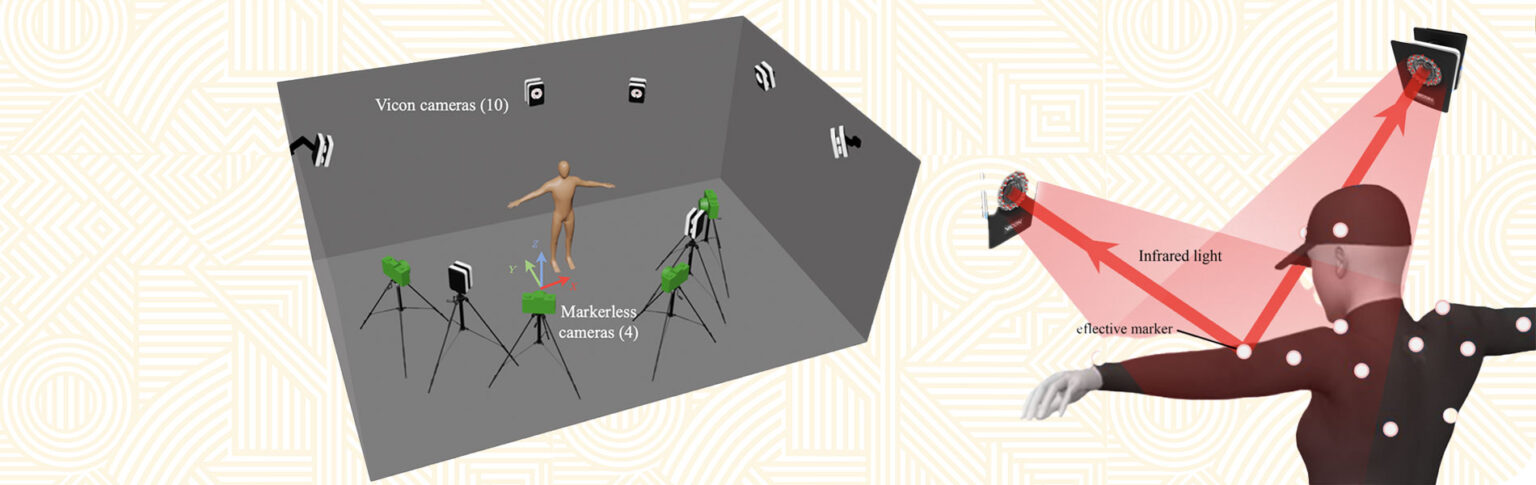
Graphic 1: Ten Vicon cameras and four markerless cameras surround the subject and view the same action sequence. The world coordinate system is also shown with its origin on the ground to the right of the subject.
Graphic 2: The Vicon motion capture system at the Neuromechanics Facility at Coetzenburg was used to capture the 3D motion of subjects in the dataset. It relies on the reflection of infrared light from markers placed on their bodies and is the same technology they use for CGI modelling of actors in movies.